
Abstract
On February 22, 2024, a leading U.S. telecommunications operator experienced a 12-hour outage that caused a nationwide loss of voice and data services. The outage prevented over 92 million phone calls, including 25,000 attempts to call emergency services via 911. Similarly, a 12-hour nationwide outage in a leading telecommunication operator in Australia resulted in more than $2 billion Australian dollars in economic loss and left many customers and businesses without voice and data connectivity.
In both cases, the outage’s severity, impact, and long duration attracted significant media and public attention, raising concerns about the resilience of telecommunications networks as a society’s critical infrastructure. Consequently, official investigations were triggered to answer many questions, including a simple one: How could this happen?
These two examples highlight what complex systems scientists have been warning about for a long time: complex systems, such as telecommunications networks, are fragile. This fragility is not apparent but hidden – by design.
This article follows my previous post and discusses two real-life examples where a new software deployment or configuration change caused a network-wide outage. In addition, it presents a four-stage outage curve, which shows the outage development in relation to time and impact. Understanding the nature of outages caused by software change is essential for developing preventative strategies that reduce their occurrence likelihood, impact, and duration.
Introduction
My previous article highlighted that while less than 20% of the total outages in the EU’s telecommunications networks occur due to a fault during software change, either in the software deployment or configurations. These software changes faults result in more than 77% of the total lost user hours. In addition, the article estimated that there is a $3.2 billion yearly market opportunity if lost hours due to software deployment and configuration changes are significantly reduced.
Before discussing how to avoid such outages or reduce the likelihood of their occurrences, it is essential to understand how they develop and progress. One way to do that is to study some real-life outage examples. While several online sources list major telecommunication outages in Europe, accurate technical details of these outages are not often known. Apart from the anonymized outage statistics, the European Network and Information Security Agency – the agency responsible for collecting and analyzing outage data – does not provide detailed information about each type of outage.
Therefore, this article analyzes two outages: one from AT&T in the U.S. and the second from Optus in Australia. This is because the U.S. Federal Communications Commission (FCC) and Australian Communications and Media Authority (ACMA) issued public reports providing detailed information about these outages. In addition, the telecommunications markets in North America, Europe, and Australia are similar as they are all considered developed markets with similar technology mix and subscriber adoption [1].
AT&T: faulty configuration in a single network element causes a nationwide 12 hours outage
The 22nd of February 2024 was unlike any other day for AT&T, a major telecommunication operator in the U.S. While the day’s specialty was known towards the end, the very early hours started as any typical day until 2:45 AM, which marked the beginning of a 12-hour outage. Just three minutes before that, precisely at 2:42 AM, an engineer deployed a new network element for capacity expansion. Deploying new elements happens frequently in a network that grew by 30% between 2020 and 2023 [2].
According to the FCC report published 17 months after the outage [10], the network element had a configuration fault. It was not the software that was faulty; instead, the software configuration refers to the parameters and settings that network operators adjust. The configuration fault propagated to downstream elements, which didn’t have adequate controls to handle this particular fault, as the report indicates. Consequently, these downstream elements automatically entered a “protection mode” a preventative measure. As a result, all network traffic was dropped, and new connections couldn’t be established nationwide on all radio technologies, including data, voice, and emergency calls.
The FCC report does not specify which network element was deployed; however, I assume it is a core network or transport element since (1) it was realized as software, and most of the core network functions have been “softwarized” in modern networks, (2) all technologies including 4G and 5G were impacted so it can be on the radio access side, and either in core or transport.
Telecom networks designed in a way that mobile terminals without a connection will continuously attempt to register on the network automatically. However, as these downstream network elements were in protection mode, the mobile terminals’ registration procedure was unsuccessful, resulting in a huge storm of registration requests waiting to be handled. Besides, all network KPIs were showing significant deviations from their expected values since traffic volumes have degraded significantly. Someone would imagine the difficult situation the operations team was in when trying to understand what was going on. The FCC report indicates that all AT&T’s technical and leadership teams were engaged to identify the root cause.
While the FCC report doesn’t specify how long it took the team to realize that there was no traffic on the network from when all traffic was dropped, it indicates that it took 2 hours to roll back the network change, roughly around 4.43 AM. As the registration storm was waiting to be severed, the team decided to give priority to emergency service (i.e., FirstNet), before other users. Thus, FirstNet traffic was restored at 5:00 AM, shortly after the rollback.
However, it took another 10 hours to restore the traffic nationwide. The congestion caused by the many devices trying to register was far beyond what the network could handle. Thus, to reduce the storm of registration requests, the operation’s team interfered by changing configurations and rebooting some equipment to prevent access to the network and resolve the congestion.
The story didn’t end even if the network’s KPIs returned to their expected values. Some subscribers were still unable to register. This is because they had old or faulty mobile terminals that timeout since the registration was not served during a specific time. Thus, they were locked in the emergency call state. The end user had to switch the equipment on/off to recover these terminals. Therefore, while the network was recovered from AT&T’s end after 12 hours, some users were still required to intervene manually to connect their devices.
The interesting question is, why is the configuration fault not detected before being deployed into the network? The FCC report provides surprising insights: no review, test, or validation was conducted! It started with human error, and the internal procedure was not followed. The element’s configuration was not peer-reviewed nor tested in the lab. In addition to pre-deployment testing, there was no validation once the element was placed in the network. The report indicates that the post-deployment validation was not conducted. I would imagine that persons involved in preparing the element were either very confident of their work because they either did a similar thing before without an issue or they were under heavy pressure to finalize the work. Nevertheless, while it started with a human error, the report specifies a number of other factors that contributed to such system limitations, resulting in registration congestion.
Optus: A software upgrade of a router in North America causes a 12 hours nationwide outage in Australia
The second real-life example comes from Optus, a leading Australian mobile network operator with roughly 25% market share, according to ACMA [3].
On the 8th of November, 2023, the Optus network experienced one of the worst outages in Australia’s telecommunications history. The outage lasted 12 hours, resulting in a 2 Billion Australian dollar economic loss. All mobile and fixed communications, including the ability to contact emergency services, were affected. Due to the impact and duration of the outage, the Australian Parliament started an inquiry, and the Australian Communications and Media Authority (ACMA) started an investigation [4]. As a result of the investigation, new governmental rules for network outages were drafted and came into effect by the end of 2024 [5,6].
According to the ACMA investigation report [7] and the analysis by RMIT University [8], the outage started at about 4:00 AM local time. Just before the outage began, the software of an internet exchange router was upgraded to a new version. Ironically, the internet gateway router did not belong to the Optus network; neither was it managed directly by Optus operations; instead, it is located in North America, managed and operated by Singapore Telecom (SingTel). The router is part of an internet routing backbone owned by Singtel and provided as a service to connect network operators’ networks to the internet and exchange international traffic.
When the router was upgraded, an alternative internet gateway router was selected to route the traffic. Thus, a spike of routing information updates was sent across the network (in data networking terms: Border Gateway Protocol (BGP) announcements). In such cases, changing the routing information and sending updated routing information are expected behaviors. However, while the routing information updates propagated and were handled successfully in different Optus routing layers, the amount of information was more than the default settings in the network’s edge routers. Thus, these routers couldn’t handle the routing update and shut down the IP interfaces as a protection mechanism, which is an expected behavior in such a situation! As a result, all traffic was lost, and no new connections could be established. Thus, unlike the AT&T case, no “faults” or “errors” were introduced; both the routing information spike and shutting of the interfaces are expected behaviors. The fault, however, is that the edge routers had a default buffer size setting which was lower than the number of updates in the spike.
In addition, unlike the AT&T case, where the operation team could trace the start of the outage to previous actions, there were no actions taken on the network by the Optus team before the outage. Therefore, during the morning rush hours, the updates from Optus indicated that the root cause was not found and that the technical teams were continuing their investigation. It was not until 12:54 PM that initial reports on social media indicated that telecom services were partially back [9]. Shortly after, Optus communicated that the technical team had found the issue and began the remediation.
Interestingly, the remediation was to restart the routers! Since these IP routers were shut down, restarting them remotely was not always possible as the O&M connection could not be established. Thus, a combination of remote and physical reset was performed [10].
In this case, there was no registration congestion reported as in the AT&T case. In my view, this indicates that Optus was better dimensioned to handle the storm of registration requests. However, some terminals were stuck in an emergency-call state like AT&T, thus requiring a rest by the user, as indicated by Optus communication 2 hours after the network was recovered.
Interestingly, as the connectivity between the 4G and 5G radio cells and the core network was lost, these cells did not radiate any signal, so no terminals could register using these two technologies. However, some 3G cells radiated radio signals (common channels), which led terminals to camp on these cells. I assume this is because 3G base stations had a connection with the RNC, but the RNC lost its connection with the core network, so 3G common channels were still on-air. On the other hand, the 4G/5G cells connection to the core network was lost (since there is no RNC), and thus, common channels were not active. The report from the Ministry of Infrastructure highlights the cost of that on emergency calls and also points out the need to have alternative O&M routes to connect to the radio units should the primary operation and maintenance route fail [9].
So, why were the default settings on the edge routers used instead of tuned ones? The reports do not provide a clear answer; however, someone can assume that these default settings were sufficient before and worked. However, it seems this time, the routing information update spike size, which depends on how big the routing table is at the time, was more significant than what Optus has seen before.
Software change outages: the four stages curve
While there are few differences between AT&T and Optus cases, they both show a faulty software change can expose the hidden fragility of telecommunications networks. Based on these two cases and my experience in many of similar cases in the past 17 years, outages go through four main stages as depicted in Figure [1] and summarized in Table [1].
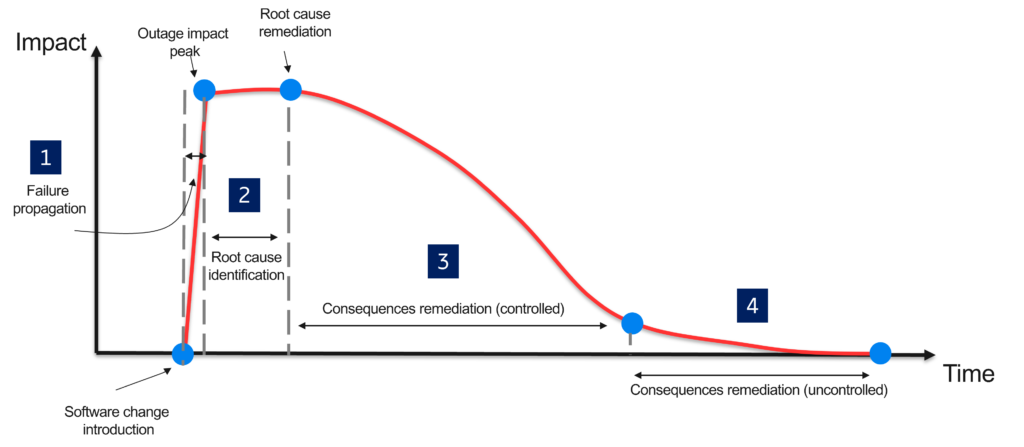
The first stage is short and starts with the introduction of the software change (deployment of new software or configuration change) until the maximum impact is reached. During this time, the change exposes internal faults or “working as designed” behaviors in downstream components. These working-as-designed behaviors are often triggered as a risk mitigation action in response to the software change. These actions increase the complexity and introduce new emergent situations in the network, leading to the outage.
In the second stage, root cause identification activities are performed. As the impact of the failure is large and spread across the network, it becomes challenging to isolate consequences from a root cause. The duration of this stage depends on the ability to correlate the start of the outage with the first software change. AT&T took a shorter time to identify the root cause (2 hours) than Optus (7 hours), as the correlation pointed to the change introduced by the software deployment conducted by the operation team. In contrast, since the change (router software upgrade) happened in an external router owned and operated by Singtel, it took more time for Optus to identify the root cause. This highlights that the impact can spill from systems beyond their control despite an operator’s control of changes introduced in their networks.
In the third stage, corrective activities are identified and executed on the impacted components controlled by the operator. These corrective activities will target the root cause (e.g., rolling back the change if needed) and “working as expected” behaviors in impacted components which are under the operator’s control.
In the fourth stage, corrective actions are applied to components beyond the operator’s control, such as mobile terminals that are left out of connection because of an internal fault or their retrial timer has elapsed. This period can be significantly long (tail) and depends on the operator’s ability to proactively identify impacted components beyond their control.

In the next article: what can be done to manage software changes so that they do not lead to an outage?
A straightforward way to avoid the risk of outages or reduce their likelihood is to have a rigorous process to test and validate before introducing software or configuration changes. Telecommunications operators have been managing change in their networks for decades using this approach. However, this approach is very slow; it often takes many months before a change is introduced, which limits the operator’s ability to respond to fast-changing market dynamics. So, is there a better way to manage new software deployments and configuration changes?
In an upcoming article, I will discuss how modern software engineering practices, particularly AIOps, GitOps, and DevOps, are essential to managing the fragility of telecommunication networks while enabling their functionality to continue evolving safely and securely.
References
[1] Global System for Mobile Communications Association (GSMA). The mobile economy 2024. https://www.gsma.com/solutions-and-impact/connectivity-for-good/mobile-economy/.
[2] Fierce Network. At&t sees 30% increase in traffic in past 3 years. https://www.fierce-network.com/wireless/att-sees-30-increase-traffic-3-years.
[3] Australian Communications and Media Authority (ACMA). Trends and developments in telecommunications 2021–22. https://www.acma.gov.au/sites/default/files/2023-07/Trends%20and%20developments%20in%20telecommunications%202021-22.pdf.
[4] Parliament of Australia. Optus network outage. https://www.aph.gov.au/Parliamentary_Business/Committees/Senate/Environment_and_Communications/OptusNetworkOutage.
[5] Australian Communications and Media Authority (ACMA). New telco industry rules for major outages. https://www.acma.gov.au/articles/2024-11/new-telco-industry-rules-major-outages.
[6] Australian Communications and Media Authority (ACMA). Acma statement on optus outage investigation. https://www.acma.gov.au/acma-statement-optus-outage-investigation.
[7] Australian Communications and Media Authority (ACMA). Investigation report and infringement notices –vsubsidiaries of singtel optus pty limited. https://www.acma.gov.au/publications/2024-11/report/investigation-report-and-infringement-notices-subsidiaries-singtel-optus-pty-limited.
[8] Mark A Gregory. An analysis of the optus national outage and recommendations for enhanced regulation. Journal of Telecommunications and the Digital Economy, 11(4):185–197, 2023.
[9] Regional Development Communications Australian Government: Department of Infrastructure, Transport and Art. Review into the optus outage of 8 november 2023 – final report. https://www.infrastructure.gov.au/department/media/publications/review-optus-outage-8-november-2023-final-report.
[10] ABC News. Two weeks since the optus outage, documents show backroom scrambling and urgent meetings occurred as the emergency played out. https://www.abc.net.au/news/2023-11-22/optus-outage-documents-behind-the-scenes-two-weeks-since/103130998.